Flexibility to Choose
Harness the power of NVIDIA, AMD, Qualcomm, Microsoft, or Cerebras by aligning each AI workload with the most suitable accelerator.
Scale Without Borders
Scale instantly with thousands of GPUs globally, supporting everything from rapid prototyping to enterprise-grade training and inference.
Built for Trust
Run mission-critical AI on secure, sovereign infrastructure designed to meet full regulatory requirements.
Who
is this for
From AI teams experimenting with the latest models to enterprises rolling out AI across thousands of users, Compass API Gateway provides the unified access, security, and control needed to scale with confidence.
.png)
Government/ Sovereign Cloud
Data sovereignty and compliance for public sector excellence across cloud, data, and AI.

Large Enterprises
Scalable infrastructure for complex operations, multi-accelerator infrastructure and go from idea to production without friction.

AI/ML Teams
Purpose-built for AI researchand production cloud with UAE-centric sovereign and security controls through Core42 Insight application
Built for Choice, Scale, and Trust
Core42 AI Cloud brings together diverse accelerators, AI-optimized infrastructure, and production-ready inference in one platform at scale.
Multi-Accelerator Platform
Harness the power of NVIDIA, AMD, Qualcomm, Microsoft, or Cerebras by aligning each AI workload with the most suitable accelerator.
Global Scale, Sovereign Infrastructure
Access 86K+ GPUs across sovereign data centers globally.
AI-Optimized Storage
Accelerate large-scale training and high-concurrency workloads with fast, resilient storage.
Proven HPC Performance
Built on globally ranked Top500 and IO500 infrastructure for high-performance AI workloads.
Core42 Compass Inference
Deploy leading models with low latency, built-in scalability, and sovereign-grade control.
.jpg?width=947&height=582&name=Frame%2013%20(1).jpg)






.png?width=834&height=834&name=b200%20(2).png)





%20(1).jpg)
From Pilot to Production Inference
Core42 Compass unifies leading AI models, scalable inference, and built-in governance, eliminating the complexity of deploying AI at scale.

.png?width=1316&height=78&name=Group%202147205557%20(1).png)
Unified Model Access
50+ industry leading models, including GPTs and open-source models across text, vision, speech, and embeddings all through one unified API.
Secure & Sovereign Deployment
Secure your GenAI deployments with in-country data residency, private endpoints, end-to-end encryption, guardrails, and enterprise-grade access controls.
Production-Scale Inference
High throughput processing capable of handling hundreds of millions of tokens in minutes from prototype to enterprise rollout.
Agentic Workflows
Build AI agents, multi-step orchestration, tool-calling systems, and autonomous workflows with production-ready frameworks.
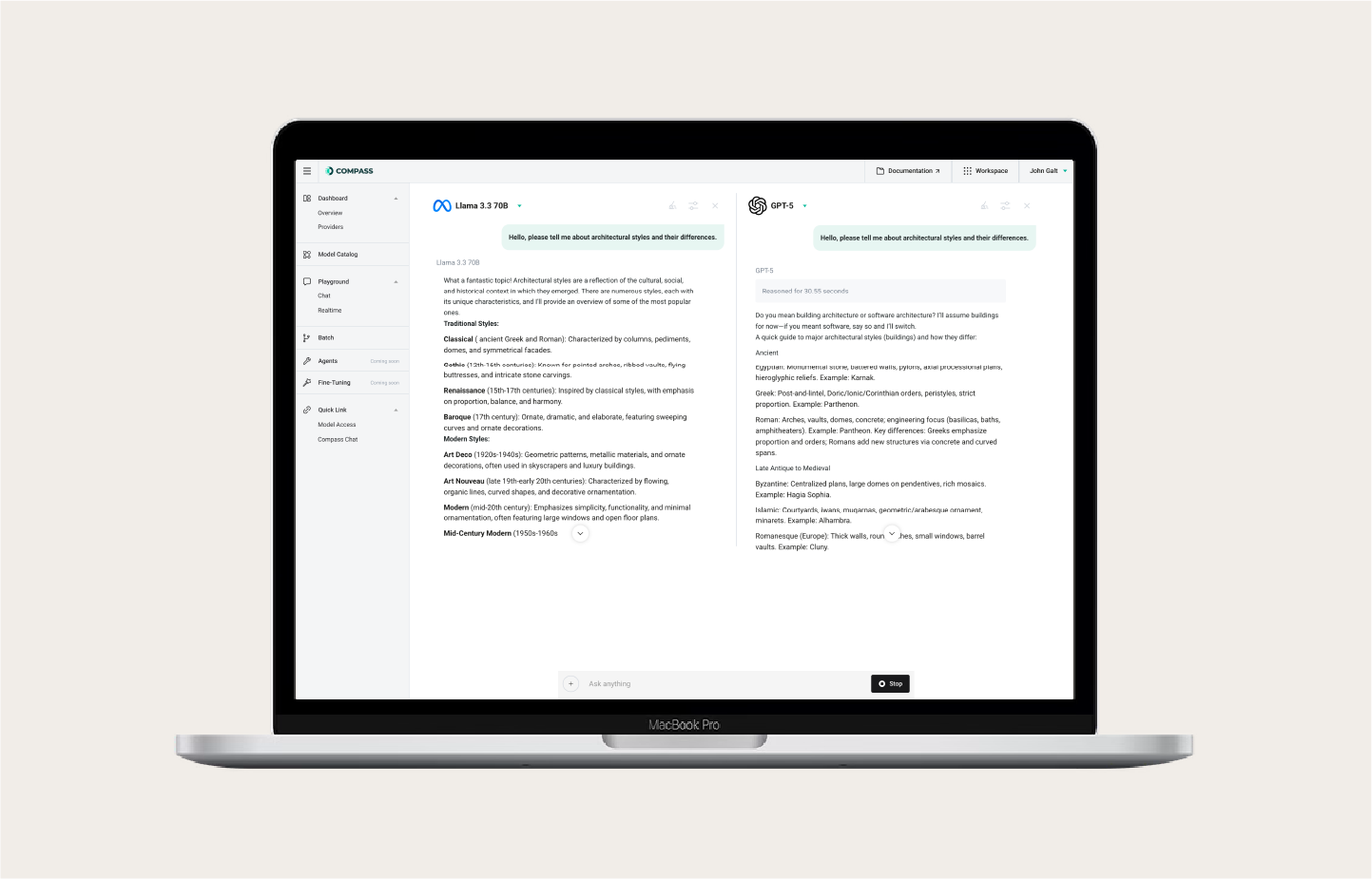
Compass Playground
Experiment with prompts, test models, and validate performance before production.
Fine-Tuning Services
Customize models to your domain with fine-tuning services and optional white-glove support from data preparation to deployment.
GenAI Services

Core42 Compass Inference

AI OPS

Infrastructure as a Service

Core
Benefits
Experiment, build, and scale GenAI seamlessly with Core42 Compass, combining startup speed with enterprise-grade control, 24×7 support, and 99.5% uptime.

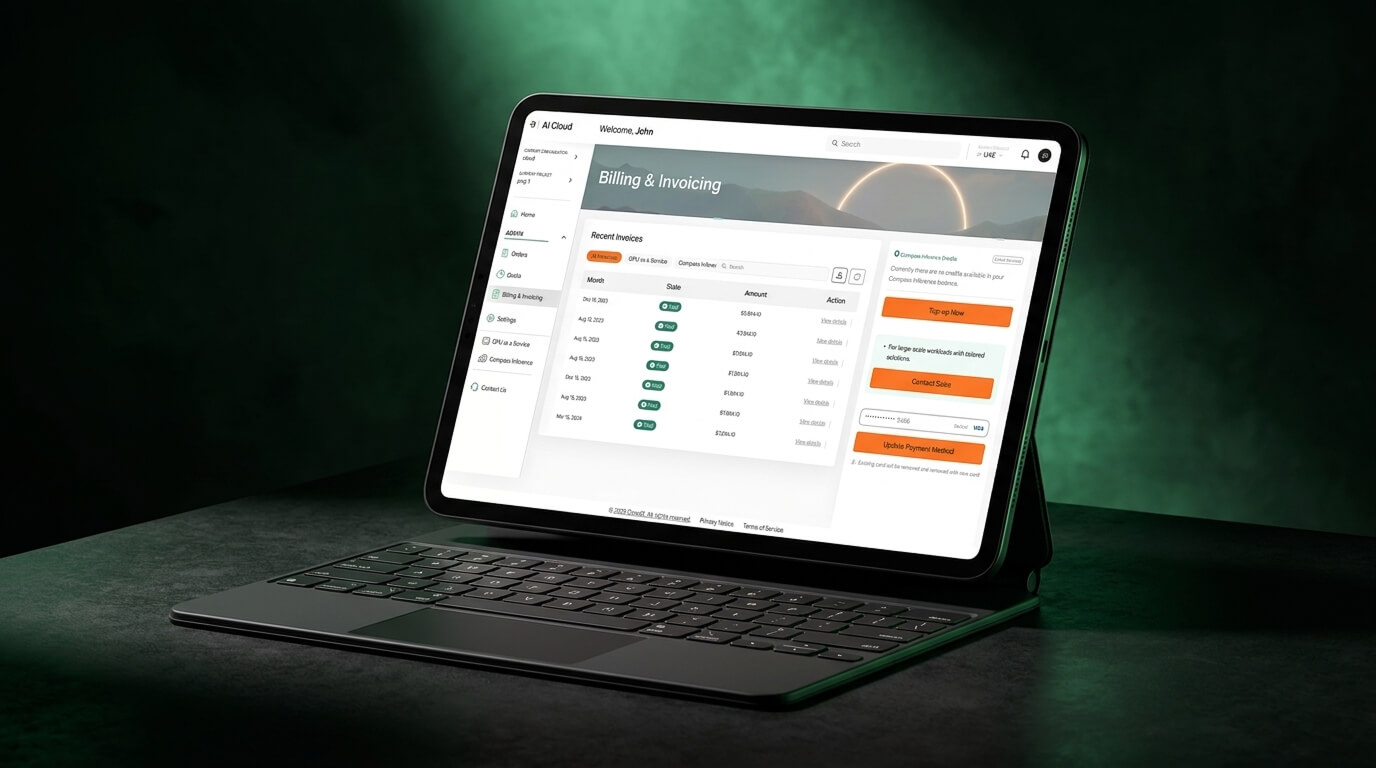
Data Sovereignty
Keep AI models and data exchanges fully within UAE borders with comprehensive sovereign policies.
Powerful Unified API
Access leading AI models through a single API. No multi-vendor complexity, no performance trade-offs.
Flexible Deployment Options
Choose cloud or on-premises deployment with infrastructure tailored to your unique security, performance, and compliance needs.

Future-Ready Architecture
Stay ahead of rapid AI advancements with a platform that evolves alongside your needs and maximizes long-term value.

How it works
Architecture overview
GenAI Services
Model Hosting & Inference
AI Ops
Infrastructure-as-a-service

AI-optimized storage
networking
kubernetes & slurm
management
management
Trusted by Industry







Resources
Start your AI journey with the insights, tools, and resources to turn ideas into production-ready solutions.

%20(Medium).png)